






.svg)

.svg)


Testing
TESTING

Automated testing to validate user experiences across real devices, networks, and channels.
Features
CHANNELS
Automated testing to validate user experiences across real devices, networks, and channels.

Software development is moving fast. Traditional testing practices are still critical, but they don’t always catch the edge cases that show up in today’s complex, distributed production environments. That’s where testing in production becomes valuable.
Despite the name, testing in production doesn’t mean skipping best practices or experimenting recklessly on users. It means adding an extra layer of validation in the real environment using controlled checks, real traffic patterns, and production telemetry. These sanity checks help catch defects that inevitably slip past pre-release testing.
In this article, we’ll explain why testing in production has become increasingly important, how to implement it safely, and which strategies help improve quality without putting user experience at risk.
Summary
1.
Why test in production?
2.
The roles of production testing
3.
How to set up production testing
4.
Production testing strategies and techniques
5.
Success metrics
6.
Key takeaways
7.
8
9.
10.
Production environments are far more complex than they were just a few years ago. Third-party dependencies keep multiplying, users access services from an ever-wider mix of devices and networks, data volumes keep growing, and software changes never really stop.
Building a staging environment that perfectly mirrors production is unrealistic. Between payment providers (PSPs), external APIs, browser variability, mobile device diversity, and privacy constraints that limit how closely you can replicate real data, some production conditions simply cannot be reproduced with full fidelity. In many cases, the only place you can validate behavior under real constraints is the environment where those constraints actually exist.
Modern software delivery is defined by speed. Many teams now ship weekly, daily, or multiple times per day. That pace changes the testing equation: you cannot rely only on pre-release validation and hope it covers every edge case.
Testing in production helps teams release frequently with more confidence. By shipping smaller changes, rolling them out gradually, and monitoring outcomes in real time, teams can detect anomalies quickly and respond before issues spread. Over time, frequent releases also improve operational maturity: teams get better at assessing risk, observing outcomes, and making safer changes.
Like any testing approach, production testing aims to catch defects. The difference is what it targets: issues that only show up under real-world conditions, such as specific third-party behavior, unexpected traffic patterns, configuration drift, or rare device and browser combinations.
Production testing focuses on validating key customer journeys end to end, under actual operating conditions.
It also helps catch misconfigurations or data inconsistencies that can exist even with a strong staging environment. Finally, it provides a way to observe performance under unpredictable circumstances, such as dependency slowdowns or sudden load spikes, before they turn into widespread incidents.
Production testing can serve different purposes depending on the organization. The most immediate role is early detection: well-designed probes, synthetic checks, and monitoring can surface problems before support tickets arrive.
A second role is continuous user experience improvement. By observing real journeys, teams can identify friction points, drop-offs, cart abandonment, or UI failures that impact conversion and retention. A/B testing in production fits into this category as well: controlled experiments that compare variants to determine what performs best.
A third role is resilience validation. Production testing helps verify availability and robustness by detecting outages quickly and shortening time to recovery. It is not about “testing everything live,” it’s about continuously validating what matters most and responding faster when conditions change.
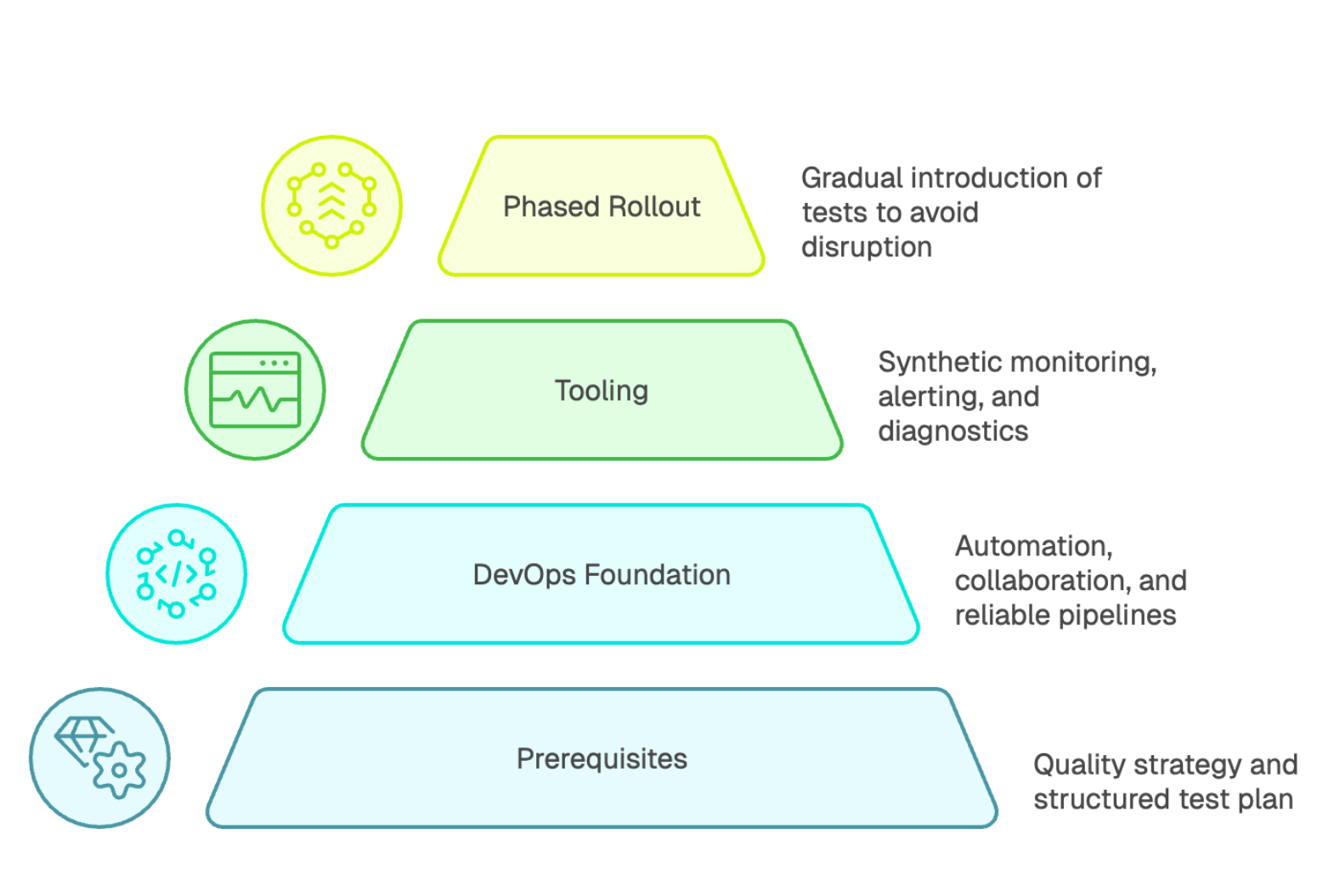
Production testing should not be improvised. It needs to be part of a broader quality strategy and fit within a structured test plan. It complements pre-release testing, but never replaces it. Unit tests, integration tests, and functional tests remain essential.
A solid DevOps foundation also matters: automation, collaboration between engineering and operations, and reliable deployment pipelines are what make production validation safe and repeatable. Teams also need the right skills, including understanding production environments, using monitoring tools effectively, and responding quickly when signals indicate user impact.
Choosing tooling is often the first concrete step. Modern production testing isn’t just “running scripts.” It typically includes synthetic monitoring, alerting, dashboards, and diagnostics so teams can detect, triage, and validate quickly.
Synthetic monitoring continuously runs scripted user journeys and API checks to detect failures before they affect users at scale. Dashboards can then be tailored by audience: engineers focus on errors and latency, while leadership tracks reliability and business-critical availability. Solutions such as Kapptivate aim to make production-grade synthetic monitoring easier to adopt by providing continuous validation for critical journeys and environments.
On budget: pricing varies widely. Depending on coverage, run frequency, and number of locations, spend can range from hundreds to thousands of dollars per month. The ROI usually comes from faster detection, fewer incidents, and reduced investigation time.
Production testing should be rolled out gradually. Start with non-disruptive checks, such as availability probes on read-only pages or lightweight health checks. The priority is simple: never interfere with real users.
Then expand coverage toward critical journeys, increasing complexity as confidence grows. Rollout and deployment practices should be designed to preserve continuity. This phased approach helps teams build skills without creating unnecessary risk. If possible, learn from people who have done this before, and standardize patterns early to accelerate adoption.
Continuous monitoring is the foundation of production validation. It includes performance monitoring (stability, latency, scalability, reliability) and user-facing performance signals (page speed, responsiveness), since slow experiences can drive abandonment before users even engage.
Monitoring typically combines multiple lenses:
Blue/green deployment uses two production environments: one serves the current version while the other is updated, then traffic is switched in a controlled way. This enables rapid rollback and reduces downtime risk.
Canary releases and dark launches apply similar logic. With a canary, a small percentage of traffic is routed to the new version to observe behavior before expanding rollout. A dark launch deploys code paths in production but keeps them hidden from users, allowing performance and load behavior to be tested safely.
More broadly, incremental delivery divides changes into smaller modules and phases, making deployments easier to validate and less risky to reverse.
A/B testing in production compares variants (UI changes, workflows, different layouts) by splitting users into cohorts and measuring outcomes.
Spike testing evaluates performance during sudden load changes and measures recovery behavior, which helps with capacity planning.
Integration testing in real conditions validates end-to-end workflows with real external partners and dependencies.
Chaos engineering goes further by injecting controlled failures (for example, terminating instances or degrading network conditions) to validate resilience and redundancy under stress.
Production feedback programs structure how you collect and analyze user input after release. The goal is to ask for feedback in targeted ways so it can be categorized and turned into action.
Beta programs gather real-world validation in user environments.
Crowd testing can also provide broad coverage, though it can be tricky for sensitive flows like payments.
Bug bounty programs bring in external security researchers to find vulnerabilities and weaknesses. Cost varies widely, but the security posture improvement is often substantial when the program is well managed.
To measure effectiveness, define clear indicators.
Start with performance metrics such as latency, page load time, and resource utilization. These help detect regressions quickly.
Track detection and resolution metrics next:
Availability targets depend on your context. “Five nines” (99.999%) is appropriate for some critical systems, but not necessary for every product.
Finally, include user outcome signals such as NPS or CSAT, alongside behavioral indicators like drop-offs or completion rates, to connect technical quality to real experience.
Testing in production is an essential complement to modern quality practices. It doesn’t replace unit, integration, or functional testing. It adds an additional safety layer where staging cannot fully match reality.
Think of the Swiss cheese model: every layer has holes, but multiple layers reduce the chance that the same defect passes through all of them. Production validation helps close gaps that appear only under real-world constraints.
Implementing this approach requires discipline, the right tooling, and a gradual rollout that builds team capability over time. The payoff is meaningful: faster detection, better visibility into real performance, improved user experience, and stronger operational confidence. With a smart strategy, automation, and continuous validation, teams can build systems that adapt to modern software complexity without sacrificing quality.

