






.svg)
.svg)
.svg)


Testing
TESTING

Automated testing to validate user experiences across real devices, networks, and channels.
Features
CHANNELS
Automated testing to validate user experiences across real devices, networks, and channels.

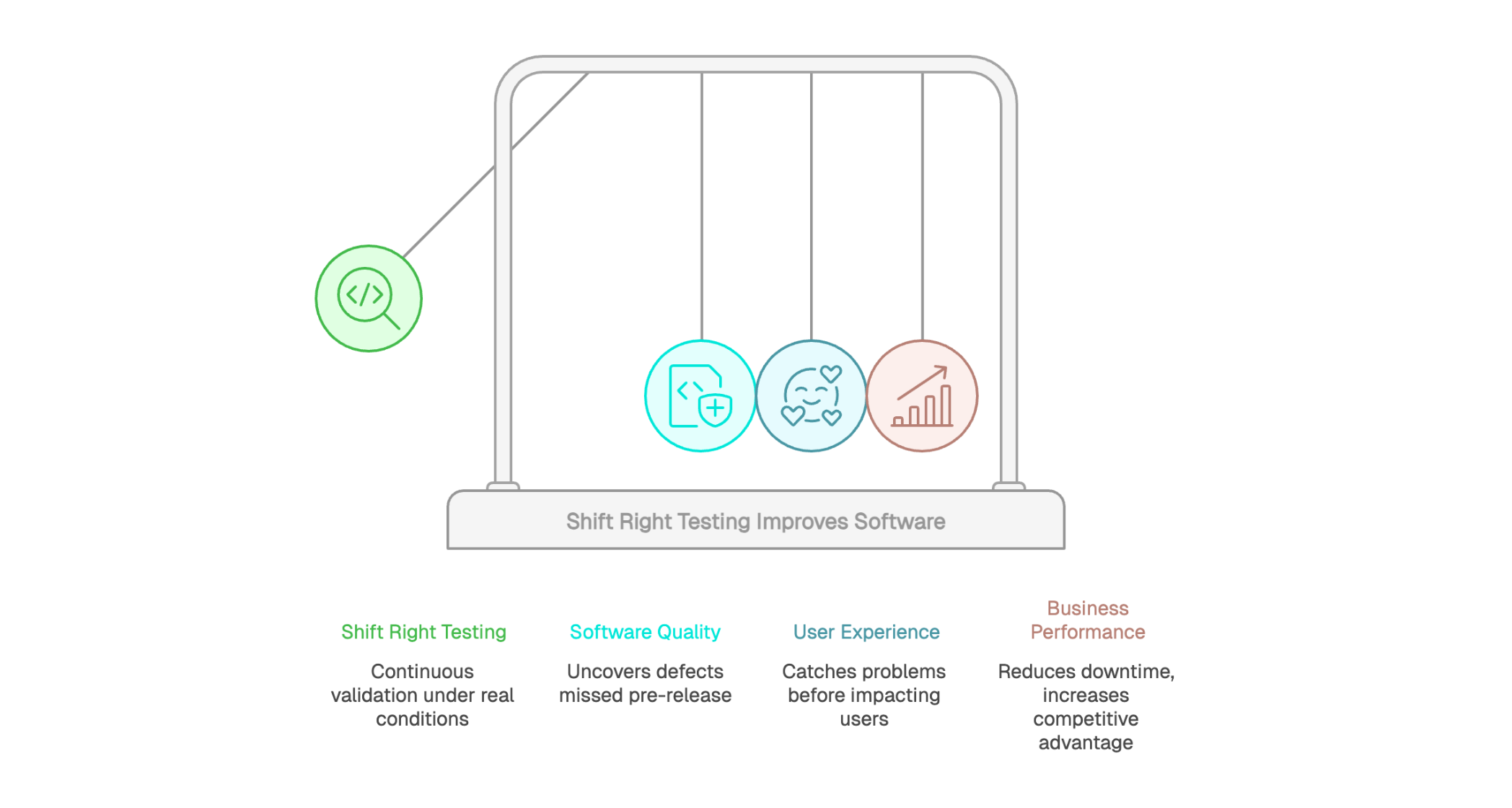
Dans un contexte où les applications logicielles deviennent de plus en plus complexes et où les attentes des utilisateurs ne cessent de croître, les méthodes traditionnelles de test montrent leurs limites. Tester uniquement en phase de développement ne suffit plus pour garantir une qualité logicielle optimale. C'est dans ce contexte que le Shift Right Testing émerge comme une approche complémentaire indispensable, permettant de valider le comportement réel des applications une fois déployées en production.
Cette méthodologie ne vient pas remplacer les pratiques existantes, mais les enrichir en apportant une vision complète du cycle de vie applicatif. Elle permet d'identifier des scénarios d'usage imprévus, de mesurer les performances réelles et de garantir une expérience utilisateur sans faille. Découvrons ensemble comment le Shift Right Testing transforme la manière dont les équipes IT abordent la qualité logicielle.
Summary
1.
Comprendre le Shift Right Testing
2.
Shift Right vs Shift Left : complémentarité, pas opposition
3.
Pourquoi le Shift Right est devenu incontournable
4.
Les bénéfices stratégiques du Shift Right Testing
5.
Guide pratique : comment mettre en place le Shift Right Testing
6.
Les méthodes de Shift Right Testing en détail
7.
L'écosystème d'outils pour le Shift Right Testing
8
Meilleures pratiques et recommandations
9.
Vers une excellence opérationnelle durable
10.
Le Shift Right Testing désigne l’ensemble des pratiques de test et de validation mises en œuvre après le déploiement d’une application, en production ou dans des environnements proches des conditions réelles d’utilisation. Contrairement aux approches traditionnelles qui concentrent les efforts de validation avant le déploiement, cette méthode prolonge la phase de test au-delà de la mise en ligne. L'objectif principal consiste à surveiller en continu le comportement applicatif, analyser les performances réelles et détecter rapidement toute anomalie susceptible d'affecter l'expérience utilisateur.
Cette approche repose sur trois piliers fondamentaux : la surveillance continue des systèmes en production, l'analyse des données utilisateurs réelles et la capacité à réagir rapidement face aux incidents. Le test en production permet ainsi de valider que l'application répond correctement aux conditions d'utilisation réelles, incluant la charge effective, les comportements utilisateurs variés et les interactions avec l'écosystème technologique complet.
Le Shift Left Testing préconise l'intégration des tests dès les premières phases du développement logiciel. Cette approche vise à identifier et corriger les défauts le plus tôt possible, réduisant ainsi les coûts de correction et accélérant les cycles de livraison. Les tests unitaires, les revues de code et les validations précoces constituent le cœur de cette méthodologie.
Le Shift Right Testing ne s'oppose pas à cette démarche mais la complète de manière naturelle. Là où le Shift Left se concentre sur la prévention en amont, le Shift Right assure la validation en aval dans des conditions réelles d'exploitation. Ensemble, ces deux approches forment un cycle de test continu qui couvre l'intégralité du parcours applicatif, de la conception à l'exploitation. Cette vision holistique permet d'optimiser la qualité logicielle à chaque étape du cycle de vie.
Les environnements de production modernes présentent une complexité sans précédent. Les architectures microservices, les infrastructures cloud distribuées et les intégrations multiples créent des conditions impossibles à reproduire fidèlement en environnement de test. Les tests en conditions réelles constituent souvent la seule manière de valider pleinement le comportement applicatif face à cette complexité.
Les comportements utilisateurs constituent un autre facteur d'imprévisibilité majeur. Malgré les scénarios de test les plus élaborés, il reste impossible d'anticiper toutes les interactions possibles. La charge réelle diffère souvent significativement des simulations, et les parcours utilisateurs empruntent parfois des chemins inattendus.
Le Shift Right Testing capture ces réalités et permet d'adapter continuellement l'application aux usages constatés. Dans un monde où la disponibilité 24/7 constitue une exigence standard, cette capacité à surveiller et réagir en temps réel devient critique pour maintenir un niveau de service optimal.
Pour la qualité logicielle, le Shift Right Testing apporte une validation continue basée sur des conditions d’exécution réelles. Il permet de détecter des défauts qui échappent aux tests pré-déploiement, liés à la charge effective, aux comportements utilisateurs imprévus ou aux interactions complexes entre services.
En s’appuyant sur la surveillance continue, l’analyse des données issues de la production et la capacité à réagir rapidement face aux anomalies, les équipes peuvent corriger plus tôt les dysfonctionnements impactant l’expérience utilisateur. Cette approche renforce la fiabilité globale des applications et permet d’améliorer la qualité perçue par les utilisateurs finaux, même après la mise en production.
L'anticipation des problèmes avant qu'ils n'impactent massivement les utilisateurs constitue un bénéfice majeur du Shift Right Testing. Grâce aux techniques de monitoring proactif et de déploiement progressif, les équipes peuvent détecter et corriger rapidement les anomalies sur un périmètre limité avant généralisation. Cette approche minimise l'impact des incidents sur la base utilisateurs globale.
L'optimisation basée sur des données réelles d'utilisation permet d'améliorer continuellement l'expérience utilisateur. Plutôt que de se fier à des hypothèses ou des tests utilisateurs limités, les équipes disposent d'informations concrètes sur les performances perçues, les points de friction et les parcours effectivement empruntés. Cette connaissance terrain guide les priorités d'évolution et garantit que les améliorations apportées répondent aux besoins réels. La satisfaction client s'en trouve naturellement renforcée, créant un cercle vertueux d'amélioration continue.
La réduction des temps d'arrêt représente un gain financier direct considérable. Chaque minute d'indisponibilité peut coûter cher en termes de chiffre d'affaires perdu et d'image de marque dégradée. Le Shift Right Testing permet de détecter plus tôt les problèmes et d’en limiter l’impact avant qu’ils ne se transforment en interruptions majeures de service, contribuant ainsi à la continuité d’activité.
L'avantage concurrentiel constitue un autre bénéfice stratégique majeur. Les entreprises capables de déployer rapidement de nouvelles fonctionnalités tout en maintenant une qualité irréprochable prennent une longueur d'avance sur leurs concurrents. Le Shift Right Testing sécurise cette capacité d'innovation accélérée en validant chaque évolution dans des conditions réelles.
Le retour sur investissement des infrastructures technologiques s'optimise également, puisque les ressources sont allouées en fonction des besoins réels constatés plutôt que sur la base d'estimations théoriques. Cette approche data driven maximise l'efficacité de chaque euro investi dans le système d'information.
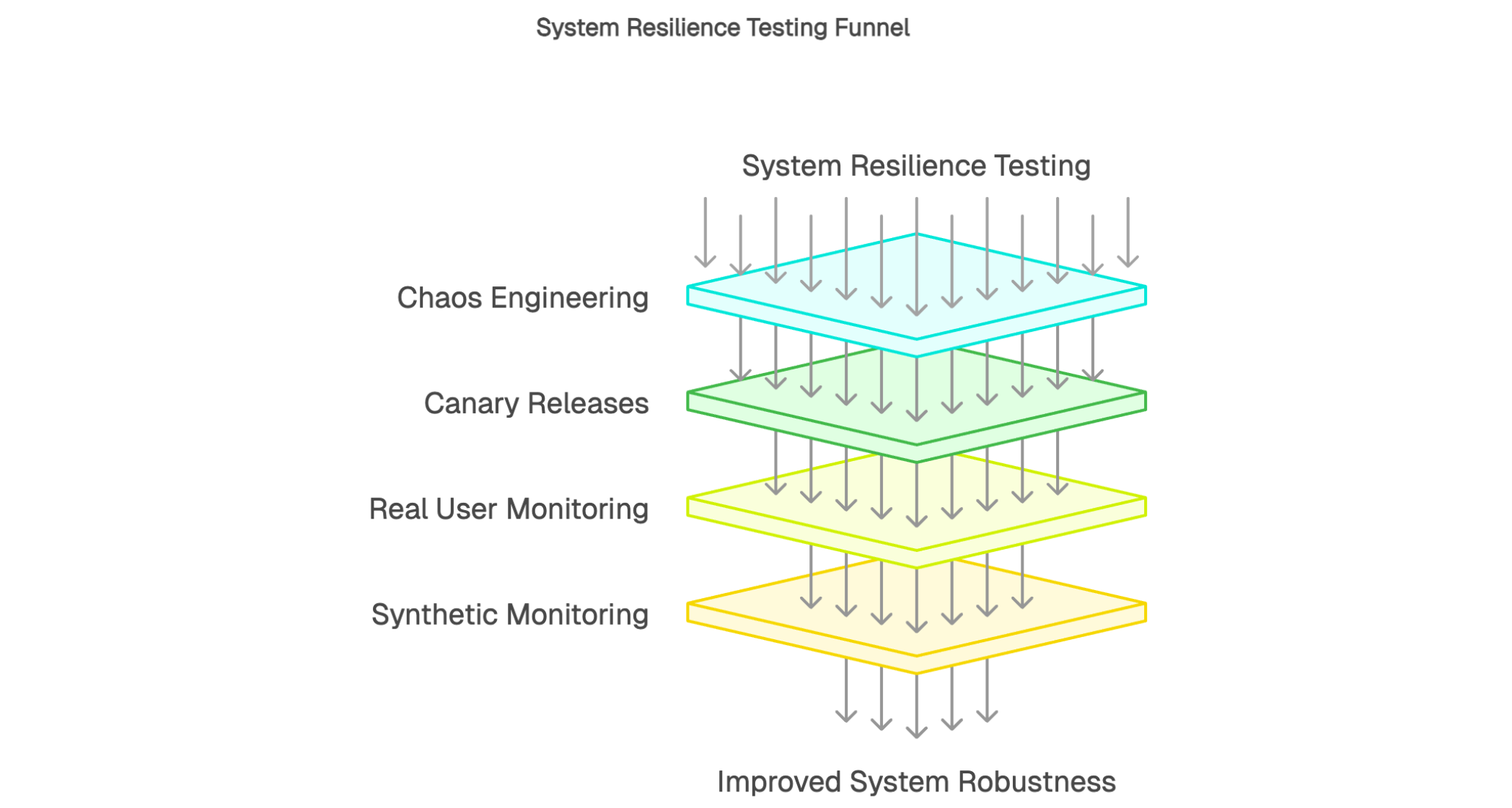
La mise en place d'un système de surveillance continue constitue le fondement du Shift Right Testing. Les outils d'Application Performance Monitoring permettent de collecter en temps réel l'ensemble des métriques critiques : temps de réponse, taux d'erreur, consommation de ressources et disponibilité des services. Cette visibilité permanente sur l’état de santé applicatif permet d’identifier rapidement les dégradations de performance et d’en analyser les causes.
Les tableaux de bord unifiés agrègent ces informations et offrent une vue synthétique de l'état du système. Les alertes automatiques déclenchées selon des seuils prédéfinis permettent aux équipes d'intervenir rapidement avant que les problèmes ne s'aggravent. L'historisation des données collectées facilite également l'analyse des tendances et l'identification de patterns récurrents, contribuant à une amélioration continue du système. Cette surveillance proactive transforme la gestion opérationnelle en passant d'un mode réactif à un mode anticipatif.
Le Real User Monitoring capture l’expérience réelle vécue par les utilisateurs lors de leurs interactions avec l’application.
Contrairement aux tests synthétiques qui simulent des comportements, le RUM mesure les performances effectives : temps de chargement des pages, latence réseau, erreurs JavaScript et fluidité de navigation. Ces données reflètent fidèlement la qualité de service perçue par les utilisateurs finaux.
L'analyse comportementale enrichit cette compréhension en révélant les parcours réellement empruntés, les fonctionnalités les plus utilisées et les points d'abandon. Ces insights utilisateurs permettent de prioriser les actions d'amélioration en fonction de leur impact réel. En croisant les données techniques de performance avec des indicateurs d’expérience et de satisfaction, les équipes obtiennent une vision complète de l'expérience utilisateur et peuvent cibler précisément les optimisations à fort impact business.
Le Synthetic Monitoring simule automatiquement des interactions utilisateurs dans des environnements proches ou représentatifs de la production.
Cette approche proactive exécute des scénarios de test prédéfinis à intervalles réguliers, validant ainsi la disponibilité et les performances des fonctionnalités critiques avant même que les utilisateurs réels ne les sollicitent. Contrairement au monitoring passif qui attend qu'un problème se manifeste, le Synthetic Monitoring détecte les anomalies de manière anticipative.
Les scénarios couvrent généralement les parcours utilisateurs essentiels : processus d'authentification, transactions commerciales, consultation de données sensibles et appels API critiques. Ces tests automatisés s'exécutent en continu, souvent depuis plusieurs localisations géographiques, garantissant une couverture étendue des parcours utilisateurs critiques. La fréquence d'exécution peut être adaptée selon la criticité des fonctionnalités, certains parcours étant validés toutes les minutes tandis que d'autres le sont toutes les heures.
Les alertes proactives générées par le Synthetic Monitoring permettent une résolution rapide avant impact utilisateur. Lorsqu'un test échoue ou que les performances se dégradent, les équipes sont immédiatement notifiées et peuvent intervenir avant que le problème n'affecte les utilisateurs réels. Cette capacité de détection précoce réduit considérablement le temps moyen de résolution des incidents et préserve l'expérience utilisateur.

Les tests canari constituent une méthode éprouvée pour valider les nouvelles versions en conditions réelles tout en limitant les risques. Cette technique consiste à déployer les évolutions auprès d'un échantillon restreint d'utilisateurs avant généralisation. Le comportement de ce groupe test fait l'objet d'un monitoring renforcé permettant de détecter rapidement toute anomalie ou dégradation de performance.
Le déploiement par phases offre plusieurs avantages majeurs. Il permet de valider la stabilité des nouvelles fonctionnalités dans un contexte opérationnel réel sans exposer l'ensemble de la base utilisateurs. En cas de problème détecté, le périmètre impacté reste limité et un retour arrière peut être effectué rapidement. Cette approche prudente mais efficace sécurise les cycles de release tout en maintenant un rythme de livraison soutenu. Le monitoring durant le rollout fournit également des données précieuses sur l'adoption et l'usage effectif des nouvelles fonctionnalités.
En production, le Shift Right Testing s’appuie sur des validations automatisées post-déploiement pour détecter les régressions fonctionnelles les plus critiques. Ces contrôles, souvent non intrusifs, permettent de vérifier que les parcours essentiels continuent de fonctionner après une mise à jour ou une correction de bug, sans perturber les utilisateurs réels.
Intégrées dans des workflows de déploiement continu, ces validations s’exécutent automatiquement après chaque mise en production, sans intervention manuelle. Elles complètent les tests de régression réalisés en amont en apportant une vérification supplémentaire basée sur le comportement réel du système. Cette approche renforce la confiance dans les déploiements fréquents tout en limitant les risques liés aux effets de bord introduits en production.
Le Fault Injection Testing introduit volontairement des défaillances contrôlées dans des environnements proches ou représentatifs de la production pour valider la résilience du système. Cette approche peut sembler contre-intuitive, mais elle permet de vérifier que les mécanismes de tolérance aux pannes fonctionnent effectivement comme prévu. Les tests incluent des simulations de pannes réseau, d'indisponibilité de services tiers ou de surcharge système.
L'ingénierie du chaos pousse cette logique encore plus loin en testant le comportement du système face à des scénarios de défaillance complexes, aux effets parfois difficiles à anticiper. Cette discipline permet d'identifier les points de faiblesse avant qu'ils ne se manifestent lors d'incidents réels. Les systèmes critiques nécessitant une haute disponibilité bénéficient particulièrement de cette approche, qui contribue à améliorer leur robustesse. La validation régulière de la capacité du système à gérer les incidents renforce la confiance dans sa fiabilité opérationnelle.
La boucle de feedback collecte, analyse et améliore constitue le moteur de l'optimisation continue. Les données récoltées via l'ensemble des mécanismes de monitoring alimentent une compréhension toujours plus fine du comportement applicatif. Cette connaissance guide les décisions d'évolution et permet de prioriser les actions selon leur impact réel sur l'expérience utilisateur et les performances.
La culture d'amélioration continue s'appuie sur cette approche data driven. Plutôt que de se fier à l'intuition ou aux suppositions, les équipes basent leurs choix sur des faits mesurables et vérifiables. Chaque modification apportée fait l'objet d'une validation via les métriques de production, créant un cycle vertueux d'apprentissage et d'optimisation. Cette démarche scientifique de l'amélioration garantit que les investissements en développement génèrent un retour mesurable en termes de qualité et de satisfaction utilisateur.
L'ingénierie du chaos teste méthodiquement la résilience des systèmes en introduisant des défaillances contrôlées dans des environnements proches ou représentatifs de la production. Cette discipline rigoureuse vise à découvrir les faiblesses avant qu'elles ne causent des incidents réels. Les expériences de chaos incluent l'arrêt brutal de services, la dégradation de la latence réseau ou la simulation de pannes matérielles.
L'identification des points faibles permet d'améliorer proactivement la tolérance aux pannes du système. Chaque expérience révèle des vulnérabilités potentielles et guide les efforts de renforcement architectural. Cette approche contribue à améliorer la haute disponibilité des applications critiques en renforçant leur capacité à continuer de fonctionner face à des défaillances inattendues. L'ingénierie du chaos transforme l'incertitude en connaissance actionnable, renforçant la confiance dans la robustesse du système.
Le déploiement canari limite initialement la diffusion d'une nouvelle version à un sous-ensemble restreint d'utilisateurs. Cette stratégie prudente permet de valider la stabilité en conditions réelles avant généralisation. Le groupe canari fait l'objet d'un monitoring avancé capturant l'ensemble des métriques de performance et de comportement applicatif.
La réduction du risque de régression massive constitue l'avantage principal de cette approche. En cas de problème détecté sur le groupe canari, le déploiement peut être interrompu ou annulé avant d'affecter l'ensemble des utilisateurs. Cette validation progressive sécurise les mises en production tout en permettant de maintenir un rythme de release élevé. Le déploiement canari représente un équilibre optimal entre vitesse d'innovation et maîtrise des risques opérationnels.
Le RUM collecte des données en temps réel sur l’expérience vécue par les utilisateurs lors de leurs interactions avec l’application. Cette approche capture fidèlement les performances perçues : vitesse de chargement, fluidité de navigation, erreurs rencontrées et latence réseau. Contrairement aux tests synthétiques qui simulent des comportements types, le RUM reflète la diversité réelle des conditions d'utilisation.
L'analyse des performances, latences et points de friction UX permet d'identifier précisément les axes d'amélioration prioritaires. Les données RUM révèlent quelles pages sont lentes, quels parcours génèrent des abandons et quelles fonctionnalités posent problème aux utilisateurs. Cette connaissance terrain guide l'optimisation de l'expérience utilisateur en ciblant les actions à plus fort impact. Le RUM transforme chaque session utilisateur en source d'information précieuse pour l'amélioration continue du service.
Les simulations automatisées du Synthetic Monitoring s'exécutent en continu pour valider la disponibilité et les performances des parcours critiques. Cette surveillance proactive fonctionne 24 heures sur 24 et 7 jours sur 7, y compris durant les périodes de faible activité où certains problèmes pourraient passer inaperçus avec le RUM seul. Les tests synthétiques permettent de détecter rapidement de nombreux incidents, quelle que soit l’heure à laquelle ils surviennent.
Les tests exécutés depuis plusieurs localisations géographiques offrent une vision étendue des performances selon les régions. Un site peut être rapide pour les utilisateurs européens mais lent pour les visiteurs asiatiques. Le Synthetic Monitoring multi-géographique aide à identifier ces disparités et à orienter les actions d’optimisation afin d’améliorer la qualité de service globale.
La comparaison entre Synthetic Monitoring et RUM met en évidence leur complémentarité. Le premier adopte une approche proactive en détectant certains problèmes avant qu’ils n’aient un impact significatif sur les utilisateurs, tandis que le second mesure l’expérience réelle vécue. Ensemble, ces deux techniques forment un dispositif de surveillance cohérent couvrant à la fois la détection anticipée des anomalies et la validation de l’expérience utilisateur effective. Les cas d’usage concrets du Synthetic Monitoring incluent la validation continue des transactions critiques, la surveillance de la disponibilité des API et la vérification des temps de réponse sur les parcours métier essentiels.
Les solutions d’Application Performance Monitoring constituent un pilier technologique majeur du Shift Right Testing. Ces plateformes collectent automatiquement un large éventail de métriques techniques : temps de réponse des transactions, consommation CPU et mémoire, throughput et taux d'erreur. Elles instrumentent le code applicatif pour tracer les requêtes de bout en bout à travers les différentes couches techniques.
Les plateformes d'analyse de logs telles que ELK Stack, Splunk ou Graylog centralisent et structurent les journaux applicatifs générés par l'ensemble des composants du système. Ces outils transforment des volumes massifs de données non structurées en informations exploitables. Les capacités de recherche avancée permettent d'investiguer rapidement lors d'incidents et d'identifier les patterns suspects.
La corrélation des événements constitue une fonctionnalité clé pour l'analyse de cause racine. Un incident en production génère souvent des milliers de messages de log. Les outils d'analyse permettent de filtrer le bruit, de corréler les événements liés et de remonter jusqu'à la cause initiale du problème. Cette capacité accélère drastiquement la résolution des incidents et améliore la compréhension globale du comportement système. L'historisation longue durée des logs facilite également l'analyse post-mortem et l'identification de tendances sur le long terme.
Les solutions comme Google Analytics, Mixpanel ou Amplitude se concentrent sur l'analyse du comportement utilisateur d'un point de vue fonctionnel et business. Elles capturent les événements métier : clics, conversions, parcours et engagement. Ces données complètent les métriques techniques en apportant une vision centrée sur la valeur délivrée aux utilisateurs.
Les insights sur les préférences et parcours utilisateurs guident les décisions produit. Comprendre quelles fonctionnalités sont réellement utilisées, lesquelles sont ignorées et où se produisent les abandons permet d'optimiser la roadmap. L'analyse comportementale révèle l'écart entre l'usage attendu et l'usage réel, source précieuse d'apprentissage pour les équipes produit. Cette compréhension fine des comportements utilisateurs maximise l'impact des efforts de développement en ciblant les évolutions à forte valeur ajoutée.
Le marché du Synthetic Monitoring propose diverses solutions adaptées à différents besoins et contextes. Les critères de sélection incluent la couverture géographique des points de test, la fréquence d'exécution possible, la diversité des scénarios supportés et la richesse des mécanismes d'alerte. Certaines plateformes se spécialisent dans le monitoring de sites web, d'autres excellent dans la surveillance d'API ou d'applications mobiles.
Kapptivate se positionne comme une solution innovante dans cet écosystème. La plateforme offre une approche simplifiée du Synthetic Monitoring, rendant cette pratique accessible même aux équipes ne disposant pas d’expertises DevOps poussées. L’interface intuitive permet de créer rapidement des scénarios de test complexes sans nécessiter de compétences avancées en programmation. La couverture géographique étendue offre une vision précise des performances selon les régions.
La valeur ajoutée de Kapptivate réside également dans sa capacité d’intégration avec l’ensemble de l’écosystème de monitoring. Les alertes peuvent être routées vers les outils de gestion d’incidents existants, et les métriques collectées s’intègrent dans des tableaux de bord unifiés. Cette interopérabilité maximise le retour sur investissement en s’appuyant sur les processus et outils déjà en place. La différenciation de Kapptivate tient à son équilibre entre puissance fonctionnelle et simplicité d’usage, rendant le monitoring proactif accessible à un large éventail d’organisations soucieuses de la qualité logicielle.
Une approche multi-outils constitue la norme dans les organisations matures. Chaque catégorie d'outil apporte un éclairage spécifique : les APM surveillent les performances techniques, les outils de logs facilitent le diagnostic, les plateformes d'analyse comportementale révèlent l'usage réel, le Synthetic Monitoring détecte proactivement les problèmes et les outils de feedback capturent les perceptions utilisateurs. L'orchestration harmonieuse de ces différentes sources d'information crée une vision complète.
La centralisation des données dans des tableaux de bord unifiés permet aux équipes de disposer d'une vue synthétique de l'état du système. Plutôt que de naviguer entre multiples interfaces, un dashboard centralisé agrège les indicateurs clés de toutes les sources. Cette consolidation facilite la prise de décision rapide et la coordination entre équipes. L'intégration réussie des outils dans une stratégie cohérente transforme la multitude de données collectées en intelligence actionnable au service de l'amélioration continue.
L'adoption du Shift Right Testing doit suivre une approche incrémentale. Commencer par identifier les applications critiques dont l'indisponibilité ou les dysfonctionnements auraient l'impact business le plus significatif. Ces systèmes prioritaires constituent le périmètre initial de mise en œuvre, permettant de démontrer rapidement la valeur de l'approche et d'acquérir l'expérience nécessaire.
Le monitoring de base représente une première étape accessible : mise en place d'une surveillance de disponibilité, collecte des métriques essentielles de performance et configuration d'alertes sur les incidents critiques. Une fois ces fondations établies, la couverture peut s'étendre progressivement en ajoutant des scénarios de Synthetic Monitoring plus élaborés, en déployant le RUM et en implémentant des stratégies de déploiement canari. Cette montée en puissance graduelle permet aux équipes d'assimiler les nouvelles pratiques sans bouleversement brutal des processus existants.
Les indicateurs de performance doivent refléter fidèlement les objectifs business et techniques visés. Les métriques de performance incluent typiquement les temps de réponse, le throughput et les taux d'erreur. Les indicateurs de disponibilité mesurent le temps de fonctionnement effectif et la fréquence des incidents. Ces métriques techniques doivent être complétées par des indicateurs de satisfaction utilisateur comme le Net Promoter Score ou le Customer Satisfaction Score.
La définition de seuils d'alerte pertinents évite à la fois les fausses alertes qui génèrent de la fatigue et les seuils trop laxistes qui manquent les problèmes réels. L'affinement de ces paramètres demande du temps et doit s'appuyer sur l'analyse historique des données. Des KPIs bien choisis et correctement configurés transforment le monitoring en outil de pilotage efficace de la qualité logicielle.
La culture DevOps repose sur le principe de responsabilité partagée entre développement et exploitation. Le Shift Right Testing renforce cette collaboration en impliquant toutes les équipes dans la qualité en production. Former les développeurs aux concepts d'observabilité leur permet de concevoir des applications plus facilement monitorables. Former les équipes ops aux pratiques de test en production améliore leur capacité à interpréter les signaux et à réagir efficacement.
Les compétences en observabilité deviennent essentielles dans ce contexte. Savoir instrumenter correctement une application, comprendre les métriques significatives et interpréter les données collectées constituent des aptitudes clés. Les processus d'incident management doivent également évoluer pour intégrer les nouvelles sources d'information et les capacités de détection proactive. L'investissement dans la formation des équipes maximise le retour sur investissement des outils déployés.
L'automatisation constitue le levier d'efficacité majeur du Shift Right Testing. Les tests synthétiques automatisés s'exécutent sans intervention humaine, permettant une surveillance continue largement indépendante des aléas organisationnels. Les alertes intelligentes utilisent des règles de corrélation pour éviter les notifications redondantes et ne solliciter les équipes que lorsque nécessaire.
Les mécanismes d’escalade automatique permettent de s’assurer qu’un incident non traité dans un délai défini remonte au niveau supérieur de support. La remédiation automatique, lorsqu'elle est possible, permet de résoudre certains problèmes courants sans intervention humaine : redémarrage de services défaillants, basculement automatique sur des ressources de secours ou ajustement dynamique des capacités. Cette automatisation libère les équipes des tâches répétitives et leur permet de se concentrer sur l'amélioration continue du système.
Le Shift Right Testing s’impose progressivement comme un levier clé de la qualité logicielle moderne. En prolongeant la phase de validation au-delà du déploiement, cette approche permet de réduire l’écart entre les tests pré-production et la réalité opérationnelle. La capacité à surveiller, analyser et améliorer en continu le comportement des applications en conditions réelles transforme la manière dont les organisations pilotent la fiabilité et la qualité de leurs systèmes.
L’importance du monitoring proactif, et en particulier du Synthetic Monitoring, joue un rôle central dans cette démarche. Identifier certaines anomalies avant qu’elles n’aient un impact significatif sur les utilisateurs constitue un avantage compétitif majeur dans un contexte où l’expérience utilisateur est un facteur clé de différenciation. Les pratiques et technologies présentées dans cet article contribuent à renforcer l’observabilité des systèmes et à instaurer une dynamique d’optimisation continue fondée sur des données réelles.
Les premiers pas vers une démarche de Shift Right Testing restent accessibles à la plupart des organisations. Identifier les applications critiques, déployer un monitoring de base et étendre progressivement la couverture permettent d’amorcer cette transformation de manière pragmatique. Les bénéfices apparaissent souvent dès les premières étapes, notamment en matière de détection des incidents, de compréhension des performances réelles et d’amélioration de l’expérience utilisateur.
Dans ce contexte, kapptivate se positionne comme un partenaire de confiance pour accompagner les équipes dans la mise en œuvre d’un monitoring proactif et opérationnel. En combinant simplicité d’usage et couverture fonctionnelle étendue, la plateforme permet aux organisations d’avancer vers une excellence opérationnelle durable, sans complexité excessive.

