






.svg)
.svg)
.svg)


Testing
TESTING

Automated testing to validate user experiences across real devices, networks, and channels.
Features
CHANNELS
Automated testing to validate user experiences across real devices, networks, and channels.
Imaginez votre écosystème digital comme une ville en pleine expansion. Des milliers d'utilisateurs s'y connectent chaque jour, naviguent entre les pages, effectuent des achats. En coulisses, des dizaines de composants interagissent en permanence : APIs, bases de données, services tiers, scripts front-end. Cette complexité croissante des environnements applicatifs modernes crée un défi majeur : comment savoir réellement ce qui se passe dans cet écosystème digital ? Comment détecter un problème avant qu'il n'impacte vos utilisateurs et votre chiffre d'affaires ?
C'est là tout l'enjeu de l'observabilité. Elle vous offre une vision à 360° de votre système, vous permettant d'être alertés et de comprendre rapidement les incidents et anomalies à corriger dans vos services digitaux. Dans un monde où chaque seconde de ralentissement peut faire fuir un client, l'observabilité est une nécessité stratégique.
Summary
1.
Définition : l'observabilité expliquée simplement
2.
Observabilité et monitoring : une relation complémentaire
3.
Pourquoi l'observabilité est essentielle aujourd'hui
4.
Les piliers de l'observabilité
5.
Comment les données d'observabilité sont générées
6.
Les composants clés d’une approche d’observabilité
7.
L'observabilité en pratique : enjeux et défis
8
Les bénéfices concrets de l'observabilité
9.
Qui est concerné par l'observabilité ?
10.
L'observabilité, un investissement stratégique
L'observabilité désigne la capacité à comprendre l'état interne d'un système en observant ses données externes. Concrètement, cela revient à pouvoir analyser n’importe quelle anomalie dans vos applications, internes comme externes, même celles que vous n’aviez pas anticipées. Pourquoi cette page se charge lentement pour certains utilisateurs ? Quel composant est responsable de cette erreur ?
Plus qu'un ensemble d'outils, l'observabilité représente un état d'esprit. Elle repose sur la collecte de données de télémétrie, leur corrélation et leur analyse pour obtenir des réponses actionnables. Un système dit observable est un système que vous pouvez interroger librement et diagnostiquer efficacement, même face à des problèmes inattendus.
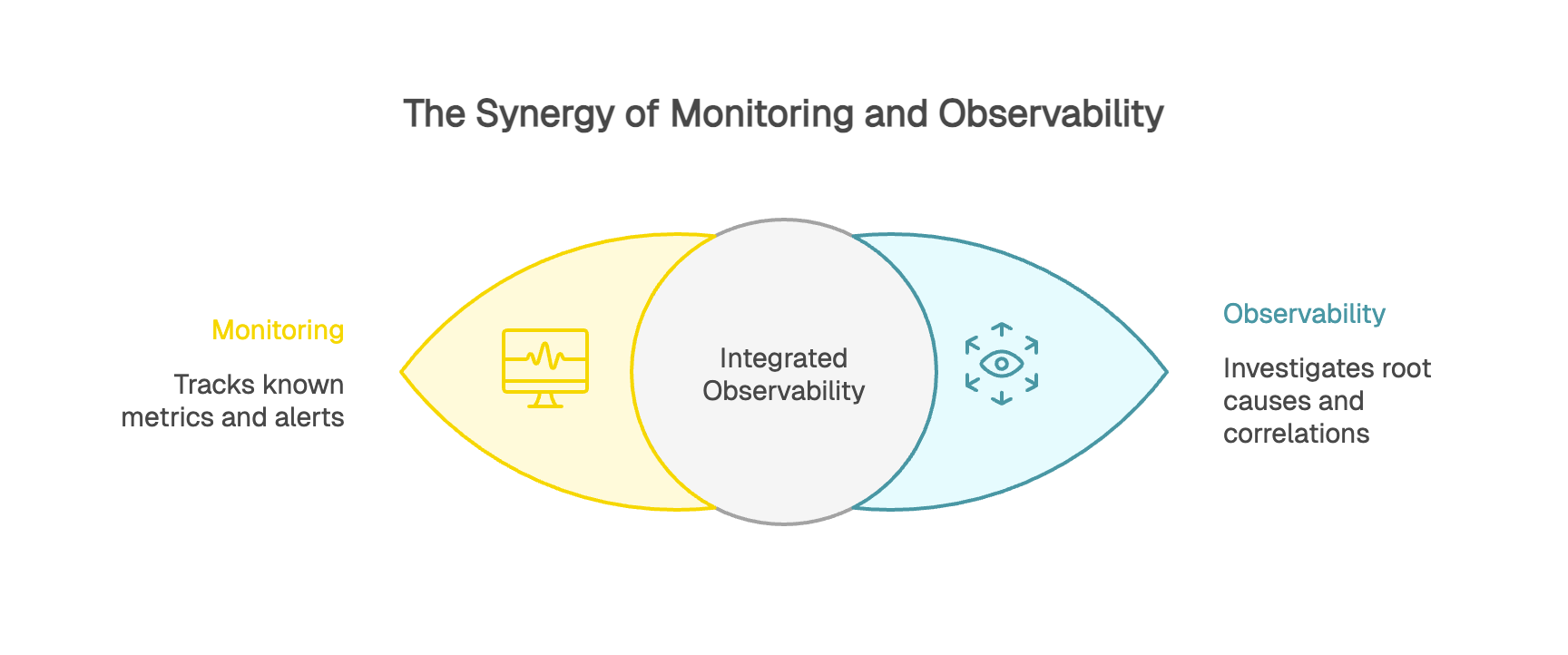
Contrairement à une idée reçue, l'observabilité et le monitoring ne s'opposent pas. Le monitoring constitue une brique fondamentale de l'observabilité.
Le monitoring répond aux questions du "quoi" et du "quand". Il surveille des métriques prédéfinies et vous alerte lorsque quelque chose sort des clous. Votre taux d'erreur dépasse 5% ? Le monitoring déclenche une alerte. C'est le tableau de bord de votre voiture qui s'allume quand la température monte.
L'observabilité répond aux questions du "pourquoi" et du "comment". Elle vous permet d'investiguer en profondeur, de corréler différentes sources et de remonter jusqu'à la cause racine. Elle vous donne la capacité de diagnostiquer précisément pourquoi votre moteur surchauffe.
Chez kapptivate, nous nous inscrivons pleinement dans cette chaîne de valeur de l’observabilité.
Nous fournissons les données et les alertes qui rendent les environnements observables, en intégrant le monitoring au cœur de notre approche globale.
Les applications web modernes sont des écosystèmes complexes. Une page de paiement peut solliciter simultanément un service d'authentification, une API bancaire, un système de stocks, un service de frais de port et une base de données client.
L’expérience utilisateur est devenue un enjeu stratégique majeur : sa qualité influence directement la satisfaction, la fidélité et la perception de votre marque. Un formulaire qui met trois secondes de trop à se charger, une page qui ne s'affiche pas correctement sur mobile : autant de frictions qui font perdre des clients. Le coût de la dégradation de performance se mesure directement en perte de revenus.
L'observabilité devient cruciale face aux "unknown unknowns", ces problèmes qu’il est impossible d’anticiper. Comment prévoir qu'une mise à jour d'une bibliothèque JavaScript provoquerait des ralentissements uniquement pour les utilisateurs Android sous Chrome 120 ? Grâce à l’observabilité, vous pouvez mettre en évidence et comprendre des anomalies, même lorsqu'aucune alerte spécifique n’avait été configurée.
L'observabilité repose sur quatre piliers de données de télémétrie qui vous offrent une vision complète de votre système. On parle souvent du modèle MELT : Metrics, Events, Logs et Traces.
Les métriques sont les indicateurs quantitatifs de performance. Temps de réponse moyen, nombre de requêtes par seconde, taux d'erreur, taux de conversion, utilisation CPU ou mémoire. Ces chiffres agrégés donnent une vue d'ensemble de la santé de votre système à un instant précis. Parce qu'elles sont agrégées, les métriques sont souvent le moyen le plus rapide et le plus économique de comprendre comment votre système performe.
Les événements (events) capturent les actions discrètes qui se produisent dans votre système. Un déploiement de code, un changement de configuration, un redémarrage de serveur, une action utilisateur critique. Les événements sont plus riches que de simples logs car ils contiennent des métadonnées structurées permettant une analyse contextuelle. Un groupe de logs peut composer un événement, donnant ainsi une vision d'ensemble d'une action complète.
Les logs constituent l'historique détaillé des événements système. Chaque action, requête ou erreur génère une trace écrite horodatée. Un utilisateur s'est connecté à 14h37, a consulté trois pages, puis a tenté de valider son panier sans succès à 14h42. Les logs capturent cette séquence et fournissent le contexte descriptif essentiel pour le débogage.
Les traces représentent le parcours complet d'une requête à travers votre système. Le tracing distribué permet de suivre une action de bout en bout, de mesurer le temps à chaque étape et d'identifier précisément le goulot d'étranglement. Une trace est obtenue en ajoutant un identifiant standard qui suit la requête à travers tous les composants qu'elle traverse.
Disposer de logs, métriques et traces ne suffit pas. La vraie puissance de l'observabilité réside dans votre capacité à corréler ces signaux pour identifier la cause racine.
Votre monitoring alerte : le temps de chargement front-end a augmenté de 40% depuis une heure. En corrélant plusieurs sources, vous menez l'enquête. Les logs API montrent des délais accrus. Les traces révèlent que ces lenteurs touchent les appels base de données. Les métriques indiquent un pic CPU sur le serveur. Conclusion : une requête SQL mal optimisée, déployée récemment, est la source du problème.
Sans cette corrélation, vous auriez parfois pu chercher des heures au mauvais endroit. L'observabilité transforme la réalisation du diagnostic : au lieu de naviguer à l'aveugle, vous suivez un fil d'Ariane vers la source du dysfonctionnement.
Une métrique brute perd sa valeur sans contexte. Dire que le temps de chargement moyen est de 2,5 secondes, c'est bien. Savoir que c'est 1,8 secondes en France, 3,2 secondes aux États-Unis et 4,5 secondes en Asie, c'est infiniment plus actionnable.
Les dimensions ajoutent ce contexte indispensable. Elles répondent au qui, quoi, où, quand. Vous segmentez vos données par navigateur, zone géographique, version de l'application, type d'utilisateur.
Cette granularité a un impact business direct. Votre taux d'abandon de panier augmente ? L'analyse des dimensions révèle que seuls les utilisateurs iPhone avec iOS 17 sont impactés, uniquement lors du paiement via Apple Pay. Cette précision permet de cibler votre investigation et de communiquer rapidement avec les utilisateurs concernés pendant la correction.
Maintenant que nous avons vu les quatre types de données d'observabilité, il est important de comprendre quels outils permettent de les exploiter. Les applications instrumentées émettent ces différents types de données que les outils d'observabilité collectent et analysent, créant ainsi un écosystème d'informations complémentaires.
Le monitoring d'infrastructure produit principalement des métriques système et des événements liés aux changements de configuration ou d'état. L'APM collecte des traces distribuées générées par l'instrumentation applicative, des métriques de performance (temps de réponse, throughput, taux d'erreur) et des logs applicatifs.
Le RUM capture les données techniques émises par le navigateur : timings de chargement, Core Web Vitals, erreurs JavaScript, et performances des ressources (CSS, JS, images).
Le Synthetic Monitoring exécute des scénarios de test automatisés et produit des métriques de disponibilité et de performance, des captures d'écran, et des états de réussite/échec pour chaque étape du parcours testé..
Cette diversité de sources et de types de données est précisément ce qui rend la corrélation si puissante. En croisant les métriques d'infrastructure avec les traces applicatives, les événements de déploiement et les logs utilisateur, vous obtenez une vision véritablement complète de ce qui se passe dans votre système. Cette diversité de données devient véritablement puissante quand elle s'appuie sur une instrumentation standardisée (OpenTelemetry) et une propagation automatique du contexte de trace. C'est cette infrastructure qui transforme une collection de métriques en véritable observabilité : la capacité à explorer librement vos systèmes et à poser des questions nouvelles sans avoir à redéployer du code.
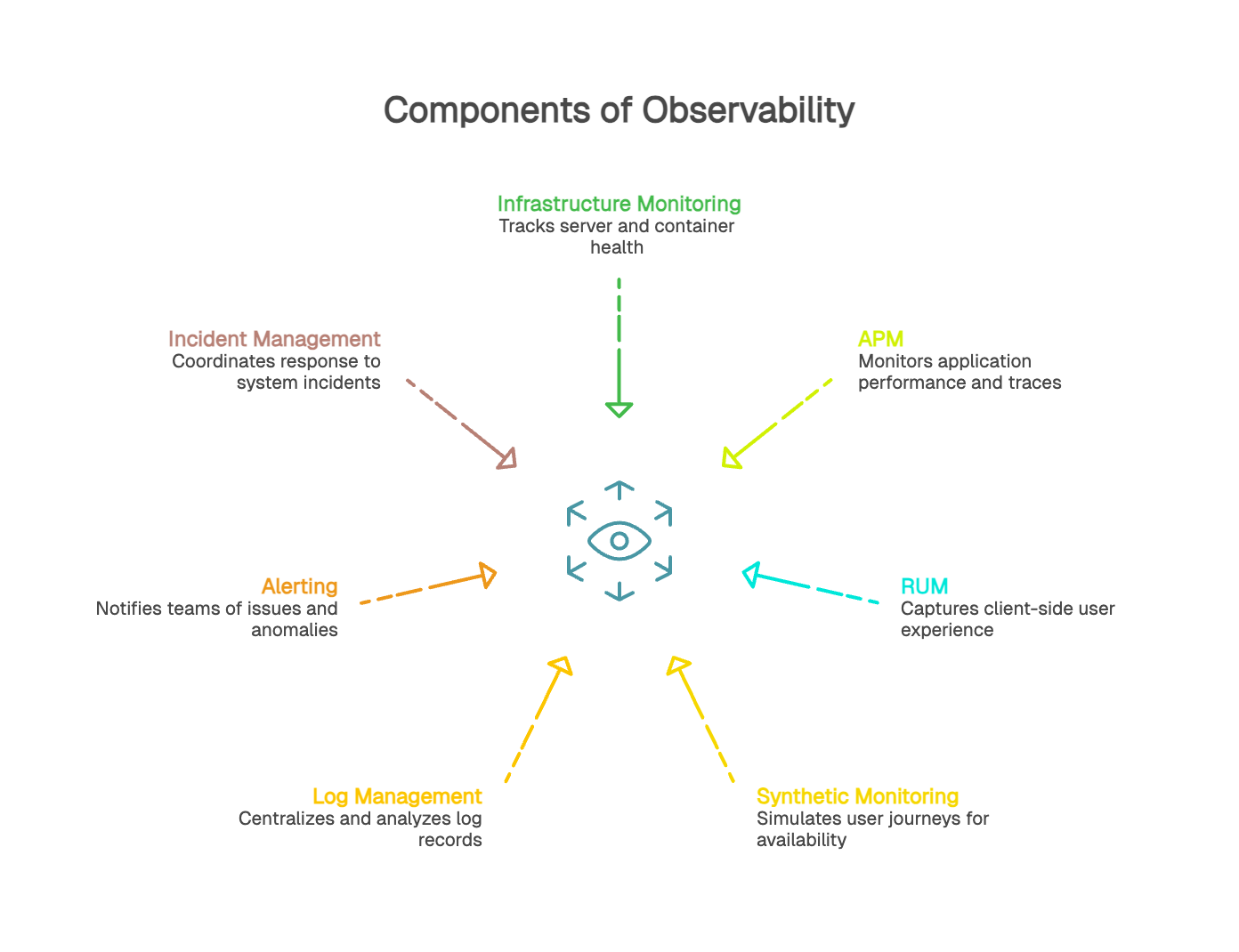
Une stratégie d’observabilité s’appuie sur plusieurs sources de signaux complémentaires. Chacune apporte un angle de lecture différent sur le fonctionnement et le comportement d’un système en production.
Le monitoring d’infrastructure suit l’état et les performances des serveurs, conteneurs, bases de données ou environnements d’exécution. Il fournit principalement des métriques système (CPU, mémoire, I/O, latence réseau) ainsi que des événements liés aux changements d’état. Ces signaux permettent de détecter les problèmes affectant les ressources sous-jacentes.
L’APM repose sur l’instrumentation de l’application pour suivre l’exécution des requêtes. Il fournit des métriques applicatives (latence, throughput), des traces distribuées organisées en spans, ainsi que des événements de déploiement. L’APM permet d’identifier rapidement où une requête ralentit et de comprendre comment le système réagit en conditions réelles.
Le RUM collecte des indicateurs de performance côté navigateur : temps de chargement, Web Vitals, erreurs JavaScript, ressources bloquantes, variations liées au device ou au navigateur. Ces données reflètent la perception réelle de l’expérience utilisateur dans des contextes variés.
Le monitoring synthétique exécute des parcours définis à intervalles réguliers pour mesurer la disponibilité et la performance dans un cadre maîtrisé. Il fournit une base de référence stable, utile pour suivre l’effet d’un changement, valider les parcours critiques et détecter les problèmes proactivement ou dehors des périodes de trafic.
La gestion des logs permet de centraliser, structurer et analyser les événements générés par l’ensemble des services. Les logs offrent un niveau de détail précieux pour comprendre les causes profondes d’un comportement observé dans les métriques ou les traces.
L’alerting s’appuie sur les métriques, traces ou événements pour notifier les équipes en cas d’écart significatif ou d’anomalie. La gestion des incidents regroupe les informations pertinentes (logs, métriques, traces, timelines) afin de faciliter la résolution et la communication interne ou externe.
L’observabilité prend tout son sens lorsque l’instrumentation permet de relier métriques, logs, traces et événements au sein d’un même contexte. Cette corrélation facilite le diagnostic, réduit le temps de résolution et offre une compréhension plus claire du comportement du système.
Une application web moderne génère des millions d'événements par jour. Cette abondance pose rapidement des questions de coûts de collecte, stockage et traitement. Les stratégies de sampling intelligent et de rétention différenciée deviennent essentielles. Par exemple, conserver 100% des traces d'erreur mais seulement 1% des traces réussies, ou stocker les logs détaillés pendant 7 jours puis uniquement les agrégats pendant 90 jours.
La cardinalité désigne le nombre de combinaisons uniques possibles pour vos dimensions. Avec trois dimensions (endpoint, région, code HTTP) et 50 endpoints, 10 régions et 20 codes, vous obtenez 10 000 séries temporelles différentes. Plus votre cardinalité est élevée, plus le volume explose et plus les systèmes peinent à traiter ces informations.
Trouver le bon équilibre entre granularité et praticabilité demande de la réflexion. Avez-vous vraiment besoin de tracker l'identifiant unique de chaque utilisateur comme dimension ? Ou pouvez-vous vous contenter de catégories d'utilisateurs ?
Le RGPD impose des précautions. Comment collecter suffisamment de données pour comprendre l'expérience utilisateur sans violer leur vie privée ? La réponse passe par l'anonymisation et la pseudonymisation. Plutôt que stocker l'email complet, utilisez un identifiant hashé. Au lieu de l'adresse IP exacte, limitez-vous au pays.
Certaines données ne doivent jamais être loguées : mots de passe, numéros de cartes bancaires, données de santé. Des processus de data masking automatiques doivent éviter toute fuite accidentelle.
Commencez par identifier les points critiques. Quels parcours utilisateurs sont essentiels pour votre business ? Page de paiement, formulaire d'inscription, recherche de produits ? Concentrez vos efforts d'instrumentation sur ces zones à fort impact. Instrumentez intelligemment.
Focalisez-vous sur les événements qui ont du sens pour vos questions métier. Construire une culture de l'observabilité est aussi important que les outils : former les développeurs, encourager les product managers à formuler leurs questions en termes de métriques, impliquer le support client.
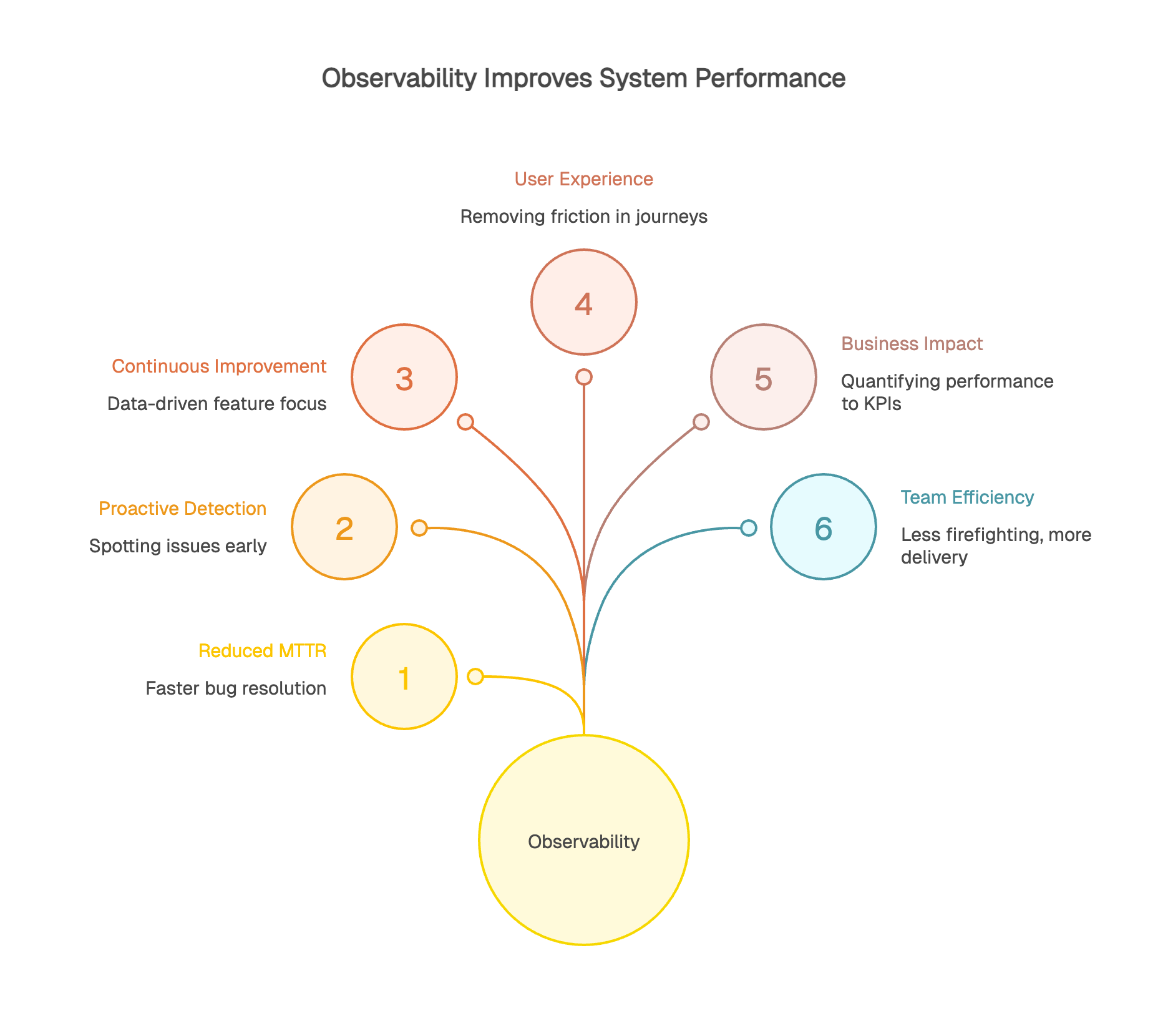
Le MTTR (Mean Time To Resolution) peut être divisé par deux, trois, voire dix avec une bonne pratique d'observabilité. Au lieu de passer des heures à reproduire un bug, vous disposez immédiatement des traces exactes du problème en production.
La détection proactive change la donne. Vous identifiez les anomalies avant qu'elles n'aient un impact visible. Une dégradation progressive, une augmentation inhabituelle d'erreurs : autant de signaux faibles que l'observabilité vous permet de capter avant qu'un problème ne prenne de l'ampleur.
L'observabilité alimente aussi un cycle d'amélioration continue. Les données réelles montrent où concentrer vos efforts. Cette fonctionnalité est-elle vraiment utilisée ? Ce refactoring a-t-il amélioré les performances ? Les chiffres donnent des réponses objectives.
L'observabilité orientée utilisateur identifie et corrige les frictions dans le parcours client. 30% d'abandon à la deuxième étape d'un formulaire ? Les traces montrent peut-être que cette étape prend 5 secondes à charger sur mobile, contre 1 seconde sur desktop.
Vous mesurez l'impact réel de vos améliorations. Après avoir optimisé une page produit, l'observabilité confirme que le temps de chargement a baissé de 40% et le taux de rebond de 15%. Ces données permettent de prioriser efficacement : vous investissez là où l'impact utilisateur est le plus fort.
L'observabilité crée un pont direct entre performance technique et KPIs business. Vous quantifiez précisément l'impact d'un ralentissement sur votre taux de conversion. Une seconde de chargement en plus correspond à combien de paniers abandonnés ? Combien de revenus perdus ?
Le ROI se calcule simplement : moins de downtime signifie plus de revenus, une meilleure expérience améliore la rétention client, l'optimisation ciblée maximise vos investissements. Certaines entreprises constatent que chaque minute d'indisponibilité coûte des milliers d'euros. Réduire le MTTR de 30 minutes à 5 minutes représente un gain considérable.
L'observabilité change le quotidien des équipes techniques. Moins de firefighting permanent, plus de recul pour l'innovation et l'amélioration continue. Avec une détection proactive et des outils de diagnostic efficaces, les développeurs se concentrent sur la valeur ajoutée.
La collaboration s'améliore. Quand toutes les équipes partagent une vision commune, les conversations deviennent plus productives. Plus de débats stériles sur les responsabilités : les données objectives montrent le chemin et créent un langage commun dans l'organisation.
L'observabilité ne concerne pas que les équipes DevOps ou SRE. Elle apporte de la valeur à tous les niveaux de l'organisation.
Les développeurs l'utilisent pour déboguer efficacement et optimiser leurs applications. Les product managers y trouvent des réponses sur l'usage réel du produit : quelles fonctionnalités, par qui, à quelle fréquence ?
Le support client anticipe et résout les problèmes plus vite, parfois avant même qu'un client ne se plaigne. La direction obtient une visibilité sur la santé du business digital : disponibilité, impact des incidents sur le chiffre d'affaires, évolution des performances.
L'observabilité crée un langage commun dans l'organisation. Les données objectives remplacent les débats d'opinion. "Le site est lent" devient "Le temps de chargement a augmenté de 20% sur mobile en France entre 14h et 16h pour les utilisateurs iOS 17".
Cette précision facilite l'alignement. Les développeurs savent où chercher, les product managers évaluent l'impact utilisateur, le support informe les clients avec des données précises. L'observabilité démocratise l'accès à l'information sur l'état du système et crée une culture de responsabilité collective sur la qualité du service.
Dans un monde où la fiabilité des services digitaux est devenue essentielle, comprendre ce qui se passe réellement dans vos systèmes est vital. L'observabilité n'est pas un luxe réservé aux grandes entreprises tech, c'est une nécessité pour toute organisation qui opère un service digital.
Commencer ne nécessite pas de tout révolutionner. Identifiez vos points critiques, instrumentez progressivement, construisez une culture de la donnée. Les bénéfices viendront rapidement : moins d'incidents, une meilleure expérience utilisateur, des équipes plus efficaces, un impact positif sur votre business.
La question n'est plus de savoir si vous avez besoin d'observabilité, mais comment la mettre en œuvre pour en tirer le meilleur parti. La première étape : évaluer où vous en êtes aujourd'hui. Avez-vous les données nécessaires pour comprendre votre système ? Pouvez-vous répondre rapidement aux questions critiques ? Si la réponse est non, il est temps d'agir.
Face à la diversité des outils d'observabilité disponibles, une question légitime se pose : par où commencer ? Le monitoring synthétique se distingue comme le point d'entrée idéal.
Contrairement au RUM qui nécessite l'intégration de scripts dans votre application, ou à l'APM qui demande une instrumentation approfondie, le monitoring synthétique peut être déployé sans modifier votre infrastructure existante. Vous créez des scénarios qui simulent vos parcours critiques et ces tests s'exécutent automatiquement, 24/7, depuis différentes localisations.
Cette simplicité permet d'obtenir rapidement vos premières métriques de performance. Le monitoring synthétique fonctionne en continu et détecte les problèmes avant que vos vrais utilisateurs ne les rencontrent. Une API tierce qui ralentit à 3h du matin ? Vous êtes alerté immédiatement, transformant votre posture de réactive en proactive.
Le monitoring synthétique offre également un cadre de test contrôlé avec des scénarios reproductibles. Vous établissez des benchmarks fiables et mesurez précisément l'impact de vos modifications. Vous pouvez tester des scénarios peu fréquents mais critiques et surveiller vos environnements de pré-production avec la même rigueur que la production.
Chez kapptivate, nous nous concentrons sur le monitoring synthétique parce qu'il représente la porte d'entrée la plus accessible vers l'observabilité. Notre plateforme vous permet de configurer rapidement des scénarios de surveillance sur vos parcours critiques, avec un investissement maîtrisé et des résultats mesurables dès les premières semaines.

